Modern Web Scraping in 2025: The Three Strategies That Power Reliable Data Collection
The web is the world’s largest data source – but it’s also one of the hardest to access reliably.
Over the past decade, web scraping has evolved from simple scripts that fetched HTML to complex systems capable of navigating JavaScript-driven pages, dynamic content, and advanced anti-bot defenses.
Modern teams now approach scraping not as a one-size-fits-all task but as a strategic choice between multiple technologies, each with its own strengths, trade-offs, and best-fit scenarios.
This article breaks down three core strategies that define modern web scraping in 2025 – and how they work together to deliver consistent, scalable access to data across the evolving web.
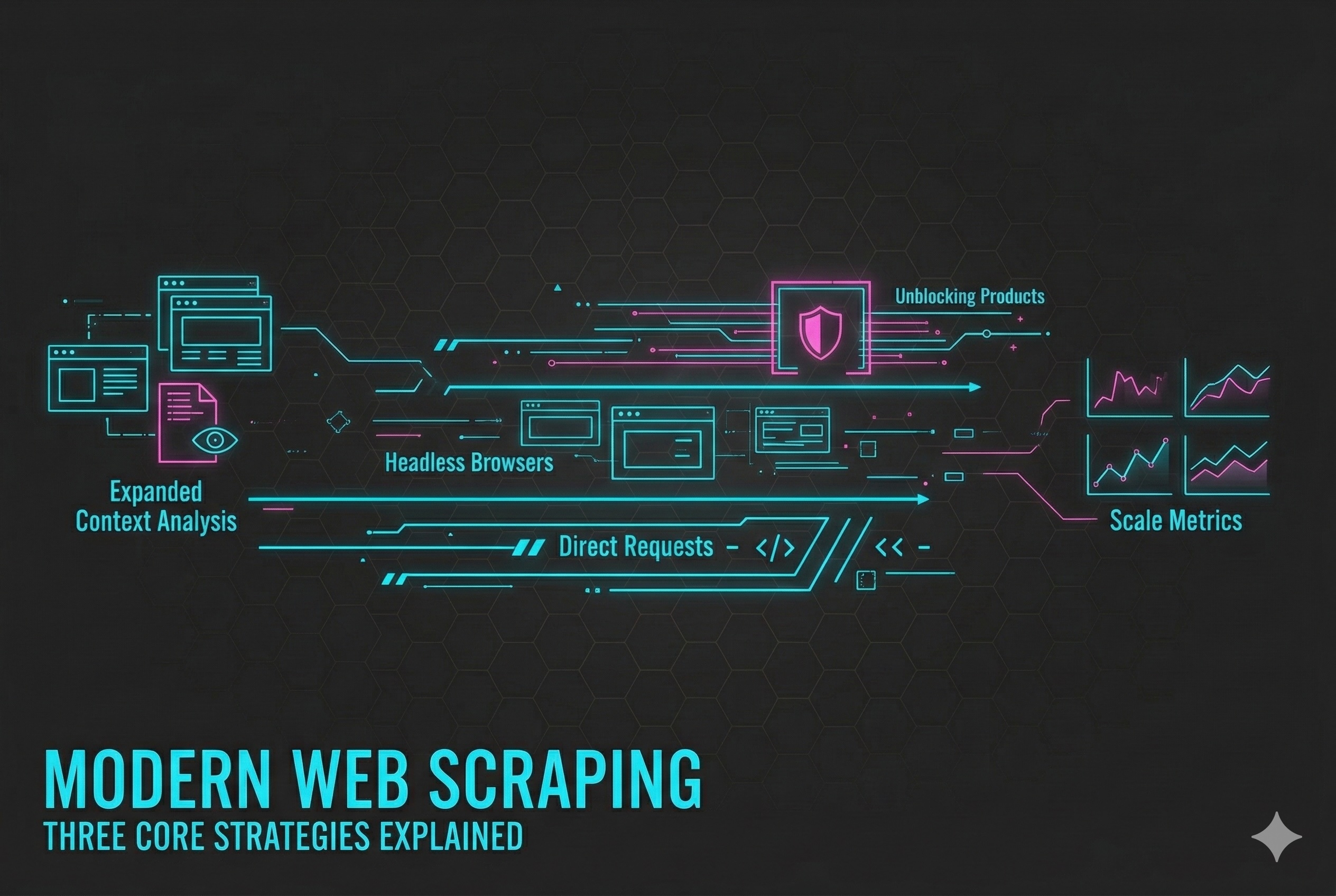
1. Direct HTTP Requests — Fast, Efficient, and Foundational
Best for: Static sites, public APIs, and predictable HTML structures
Strengths: Speed, low cost, easy to scale
Limitations: Struggles with dynamic JavaScript or anti-bot systems
The direct request method is the oldest and simplest scraping technique.
A script sends an HTTP request to a web server, retrieves the response (often HTML or JSON), and parses it for relevant data.
For many cases – such as RSS feeds, static content pages, or open APIs — this approach remains unbeatable in simplicity and speed. It’s light on resources, easy to deploy, and scales horizontally across thousands of URLs.
But the modern web complicates this picture. Many sites use client-side rendering, where the raw HTML contains little or no meaningful data. Others deploy bot-detection mechanisms that identify automated requests by analyzing headers, patterns, or timing.
Ideal when:
- The content is available in the initial HTML or API response
- You’re scraping high volumes of relatively simple targets
- Speed and efficiency outweigh complexity
Keep in mind: direct requests are most effective when paired with responsible throttling, rotating identifiers, and caching to avoid unnecessary load.
2. Headless Browsers — Rendering the Modern Web
Best for: JavaScript-driven pages, SPAs, and interactive elements
Strengths: Full DOM rendering, realistic interactions, content completeness
Limitations: Higher resource use, slower execution, complex scaling
Frameworks like React, Vue, and Angular have changed how the web delivers content – and headless browsers emerged to meet that challenge.
Tools such as Puppeteer, Playwright, and Selenium (in headless mode) simulate a full browser environment that can execute JavaScript, trigger user actions, and render asynchronous data.
This approach allows scrapers to:
- Wait for dynamically loaded content
- Interact with UI components (scrolling, clicking, filling forms)
- Capture the same data that a real user would see
It’s the most accurate way to scrape today’s front-end-heavy websites.
However, it comes with significant resource overhead. Managing many concurrent browser instances demands careful orchestration, queueing, and load balancing.
Ideal when:
- Content depends on JavaScript rendering
- Interaction is required to reveal data
- The target uses frameworks like React, Vue, or Angular
Tip: mix headless rendering selectively – render only pages that need it, while keeping others on lightweight direct requests.
3. Unblocking Products — Managed Access to Protected Data
Best for: Geo-restricted, rate-limited, or anti-bot-protected targets
Strengths: Reliable access, simplified infrastructure, high success rates
Limitations: Higher cost, third-party dependency, reduced control
The newest and most advanced layer in the web-scraping toolkit is unblocking products – managed platforms that ensure consistent access to data even on sites with sophisticated protection.
Rather than writing your own bypass logic, these systems handle the heavy lifting through:
- Automated IP rotation and geo-routing
- CAPTCHA solving and challenge handling
- Browser fingerprint and session management
- Compliance and observability controls
Some unblocking solutions go further, offering data-access APIs that abstract the scraping entirely – delivering normalized, ready-to-consume data.
These services trade control for convenience. They excel where in-house solutions would become unstable or non-compliant but may come with higher operational costs and vendor constraints.
Ideal when:
- Targets have strong anti-bot defenses
- Global coverage or uptime guarantees are required
- Data reliability is more valuable than scraping flexibility
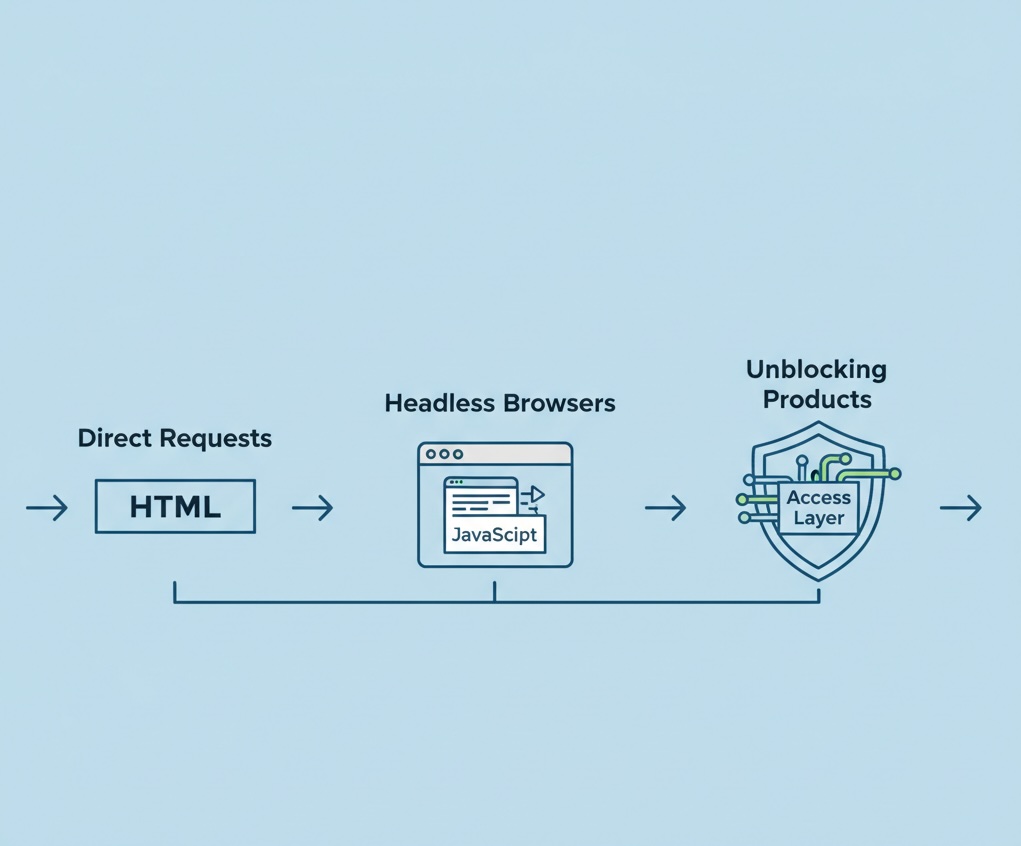
How the Three Layers Work Together
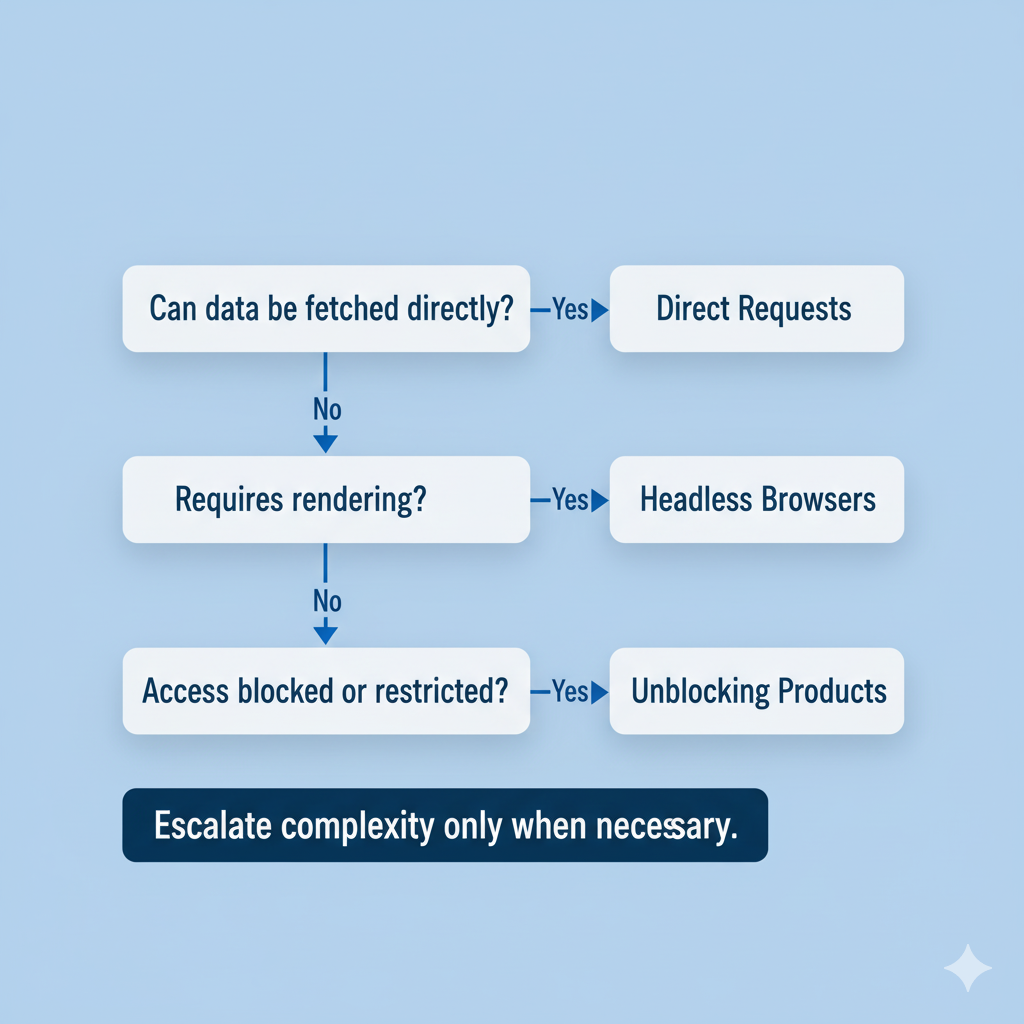
Modern scraping systems rarely rely on a single method.
The most robust architectures combine all three in a tiered pipeline:
- Start simple with direct HTTP requests for speed and scale.
- Escalate to headless browsers for dynamic or interactive pages.
- Fallback to unblocking products when access is restricted or detection occurs.
This layered model minimizes costs and latency while maximizing coverage and reliability.
| Layer | Core Strength | Primary Use |
| Direct Requests | Speed & simplicity | Static or API data |
| Headless Browsers | Completeness & realism | Dynamic content |
| Unblocking Products | Reliability & access | Protected or restricted sites |
The Future: Intelligent Orchestration
As the ecosystem matures, the emphasis is shifting from individual tools to how these strategies are orchestrated.
Modern scraping frameworks use adaptive logic – detecting when a page fails to load fully and automatically promoting it to a higher-level method.
This approach ensures:
- Optimal resource use
- Reduced maintenance complexity
- Predictable uptime and data quality
The future of web scraping is not about brute force but intelligent automation – blending these three strategies dynamically to adapt to the changing landscape of the web.

Final Thoughts
Web scraping has matured into a multi-layered discipline that balances speed, accuracy, and accessibility.
Each method has its role:
- Direct Requests remain the fastest and most scalable for straightforward data.
- Headless Browsers unlock full-fidelity access to dynamic content.
- Unblocking Products ensure stable, compliant access to restricted or protected sources.
The key lies in knowing when to use which – and in designing systems that can transition fluidly between them.
In the constantly shifting environment of the modern web, adaptability is the ultimate scraping strategy.
Ready to get started?
